The action Generate audio file with AI
Modified on Wed, 12 Nov, 2025 at 2:16 PM
Purpose
Converts text content into an MP3 audio file using an OpenAI text-to-speech model. Use this action to produce spoken versions of emails, documents or extracted text so people can listen (accessibility, notifications, voice archives, IVR, etc.).
Where to add
Place this action in any scenario that has text as input (Extract Text, AI summary/translation output, email body, plain .txt files, or any action that produces text). The action outputs an MP3 file that continues through the scenario pipeline.
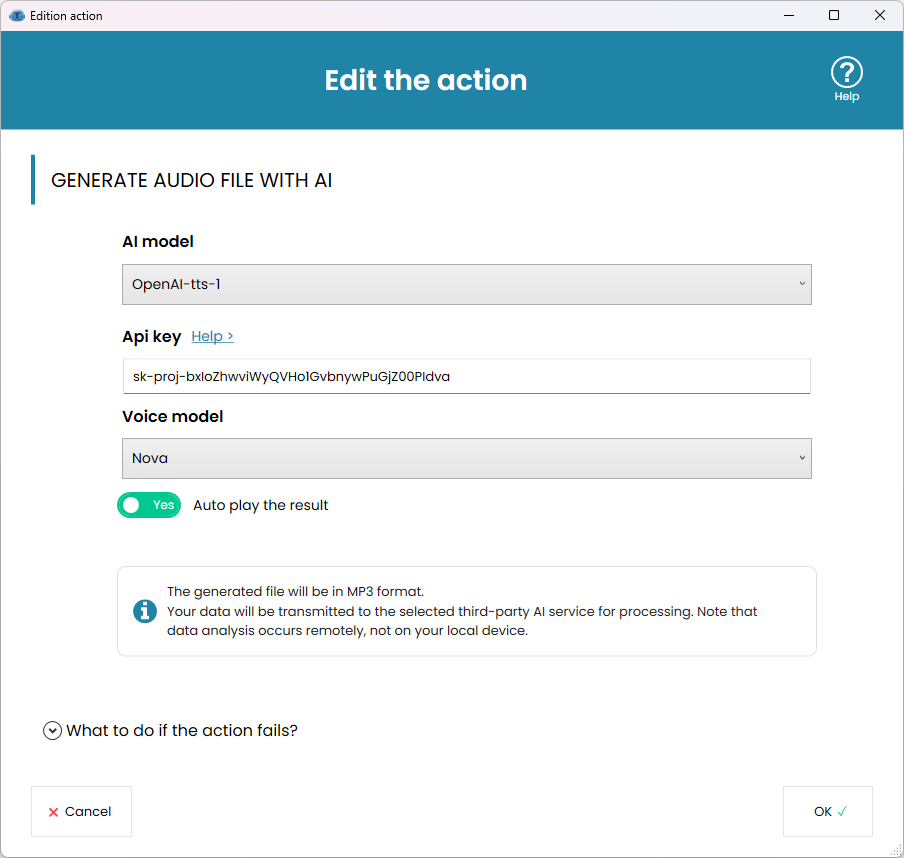
Main settings
- AI model
Select the OpenAI TTS model from the AI model dropdown. Check the UI for available models (names may change as providers add models). - API key (required)
Enter your OpenAI API key. You must have an account and API access for TTS.
Note: Get your OpenAI key here > - Voice model / Voice selection
Choose the voice (for example “Nova”, or any voice options the selected TTS model provides). Different voices change timbre, gender, and speaking style. - Auto play the result: when enabled, Rofiles will play the audio file after processing; if there are multiple files, they will be played one by one.
Output
- Result file: an MP3 audio file containing the synthesized speech. This file becomes the current output item and can be:
- Saved to disk
- Attached to emails
- Uploaded to a server
- Played or streamed by downstream systems
- Used for accessibility (reading emails/documents to users)
Supported input types
- Any text input produced earlier in the scenario: extracted text, templates, AI summaries/translations, email bodies, plain text files. For non-text sources (images, scanned PDFs) run OCR/Extract Text first.
How to configure — quick steps
- Add Generate Audio (TTS) to your scenario at the point where text is available.
- Select the OpenAI TTS model from the AI model dropdown.
- Enter your OpenAI API key in the Api key field.
- Choose a voice from the Voice model list.
- Save the action and test with a sample text.
Behavior notes and tips
- Input length and provider limits: TTS services may impose size or rate limits. For long texts, split into smaller chunks and synthesize sequentially.
- Accessibility use: combine with Extract Text and Add Tags to build flows that read emails or documents for visually impaired users.
- Test different voices for clarity and appropriateness for your audience.
Privacy, compliance and security
- Audio synthesis requires sending the text to the third‑party provider (OpenAI). Ensure this is allowed by your organization’s policies and applicable regulations before enabling the action for sensitive content.
Failure handling
- Authentication errors: invalid or expired API key will prevent synthesis. Verify and update the key.
- Large inputs/timeouts: split long text into chunks. If the provider times out, re-send smaller segments.
Examples
- Read incoming emails aloud: Extract the email body, pass it to Generate Audio, then save/send the MP3 to a mobile device or voicemail system.
- Document playback for accessibility: Extract Text from PDFs and synthesize MP3s for visually impaired users.
- Voice notifications: Automatically synthesize short alerts or daily summaries and deliver as MP3 attachments.
That’s it, choose the OpenAI TTS model, supply your API key, pick a voice, and the action generates an MP3 audio file from the provided text for use in accessibility and automation workflows.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article